Aby sprostać potrzebom usług chmurowych, sieć jest stopniowo dzielona na sieć Underlay i Overlay. Sieć Underlay to fizyczny sprzęt, taki jak routing i przełączanie w tradycyjnym centrum danych, który nadal opiera się na koncepcji stabilności i zapewnia niezawodne możliwości transmisji danych sieciowych. Sieć Overlay to sieć biznesowa hermetyzowana na niej, bliżej usługi, poprzez enkapsulację protokołu VXLAN lub GRE, aby zapewnić użytkownikom łatwe w użyciu usługi sieciowe. Sieć Underlay i sieć Overlay są ze sobą powiązane i rozdzielone, a także powiązane ze sobą i mogą rozwijać się niezależnie.
Sieć bazowa stanowi fundament sieci. Jeśli sieć bazowa jest niestabilna, firma nie ma umowy SLA. Po trójwarstwowej architekturze sieciowej i architekturze sieci Fat-Tree, architektura sieciowa centrum danych przechodzi na architekturę Spine-Leaf, która zapoczątkowała trzecią aplikację modelu sieciowego CLOS.
Tradycyjna architektura sieciowa centrum danych
Projekt trójwarstwowy
W latach 2004–2007 trójwarstwowa architektura sieci cieszyła się dużą popularnością w centrach danych. Składa się ona z trzech warstw: rdzenia (szybko przełączającego szkieletu sieci), warstwy agregacji (zapewniającej łączność opartą na regułach) oraz warstwy dostępu (łączącej stacje robocze z siecią). Model wygląda następująco:
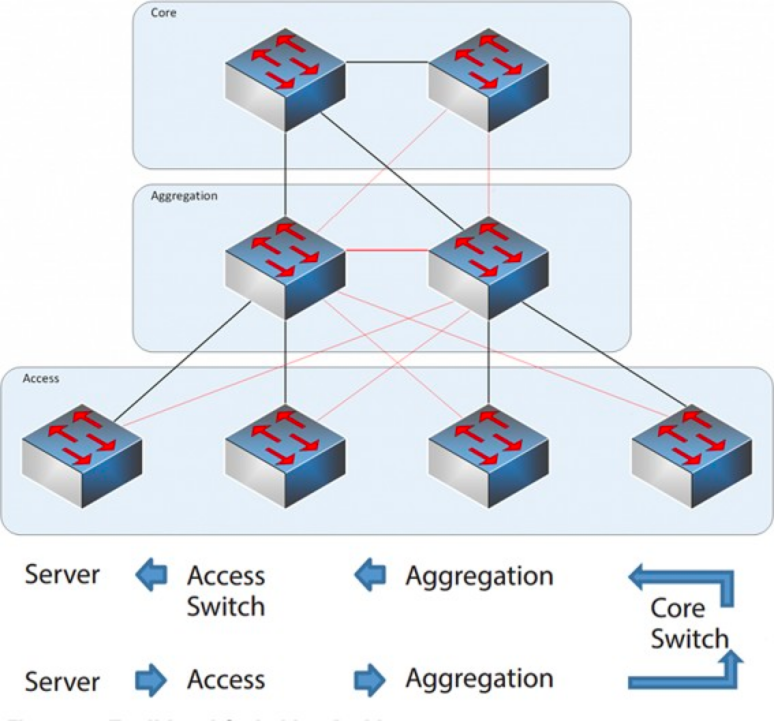
Trójwarstwowa architektura sieciowa
Warstwa rdzeniowa: przełączniki rdzeniowe zapewniają szybkie przekazywanie pakietów do i z centrum danych, łączność z wieloma warstwami agregacji oraz odporną sieć routingu L3, która zazwyczaj obsługuje całą sieć.
Warstwa agregacji: Przełącznik agregujący łączy się z przełącznikiem dostępowym i udostępnia inne usługi, takie jak zapora sieciowa, odciążenie SSL, wykrywanie włamań, analiza sieci itp.
Warstwa dostępu: Przełączniki dostępowe znajdują się zwykle na górze szafy, dlatego nazywane są również przełącznikami ToR (Top of Rack) i fizycznie łączą się z serwerami.
Zazwyczaj przełącznik agregujący stanowi punkt demarkacyjny między sieciami warstwy 2 i 3: sieć warstwy 2 znajduje się poniżej przełącznika agregującego, a sieć warstwy 3 powyżej. Każda grupa przełączników agregujących zarządza punktem dostawy (POD), a każdy POD jest niezależną siecią VLAN.
Protokół pętli sieciowej i drzewa rozpinającego
Powstawanie pętli jest najczęściej spowodowane zamieszaniem wynikającym z niejasnych ścieżek docelowych. Użytkownicy budujący sieci, aby zapewnić niezawodność, zazwyczaj używają redundantnych urządzeń i łączy, co nieuchronnie prowadzi do powstawania pętli. Sieć warstwy 2 znajduje się w tej samej domenie rozgłoszeniowej, a pakiety rozgłoszeniowe będą wielokrotnie przesyłane w pętli, tworząc burzę rozgłoszeniową, która może w jednej chwili zablokować porty i sparaliżować urządzenia. Dlatego, aby zapobiec burzom rozgłoszeniowym, konieczne jest zapobieganie powstawaniu pętli.
Aby zapobiec powstawaniu pętli i zapewnić niezawodność, możliwe jest jedynie przekształcenie redundantnych urządzeń i redundantnych łączy w urządzenia i łącza zapasowe. Oznacza to, że redundantne porty i łącza urządzeń są blokowane w normalnych warunkach i nie uczestniczą w przekazywaniu pakietów danych. Dopiero w przypadku awarii bieżącego urządzenia, portu lub łącza, powodującej przeciążenie sieci, redundantne porty i łącza urządzeń zostaną otwarte, aby sieć mogła wrócić do normalnego działania. Ta automatyczna kontrola jest realizowana przez protokół Spanning Tree (STP).
Protokół drzewa rozpinającego działa między warstwą dostępu a warstwą odbiorczą, a jego rdzeniem jest algorytm drzewa rozpinającego działający na każdym moście z włączonym protokołem STP, który został specjalnie zaprojektowany w celu uniknięcia pętli mostowania w przypadku występowania redundantnych ścieżek. Protokół STP wybiera najlepszą ścieżkę danych do przesyłania wiadomości i blokuje łącza, które nie są częścią drzewa rozpinającego, pozostawiając tylko jedną aktywną ścieżkę między dowolnymi dwoma węzłami sieci, a drugie łącze w górę zostanie zablokowane.
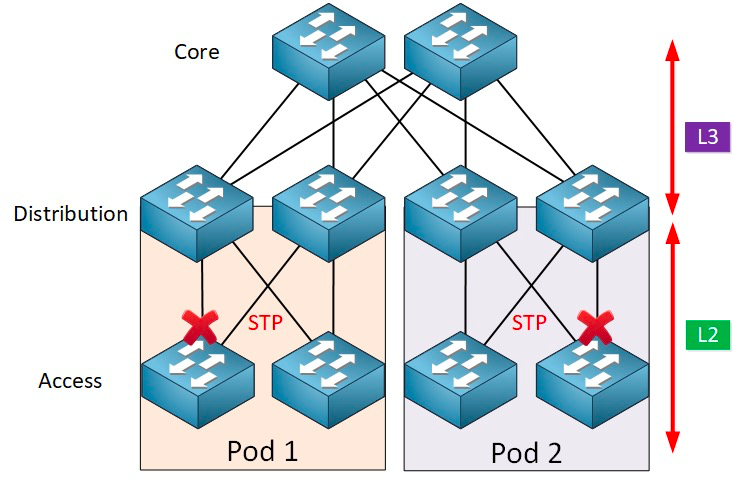
Protokół STP ma wiele zalet: jest prosty, działa w trybie plug-and-play i wymaga minimalnej konfiguracji. Maszyny w każdym podzie należą do tej samej sieci VLAN, więc serwer może dowolnie migrować lokalizację w obrębie podu bez konieczności modyfikowania adresu IP i bramy.
Jednak STP nie może korzystać z równoległych ścieżek przekierowujących, co zawsze spowoduje wyłączenie redundantnych ścieżek w sieci VLAN. Wady STP:
1. Powolna konwergencja topologii. Gdy topologia sieci ulega zmianie, protokół drzewa rozpinającego potrzebuje 50–52 sekund na zakończenie konwergencji topologii.
2. Nie może zapewnić funkcji równoważenia obciążenia. W przypadku wystąpienia pętli w sieci, protokół drzewa rozpinającego może jedynie zablokować pętlę, uniemożliwiając przesyłanie pakietów danych przez łącze, co marnuje zasoby sieciowe.
Wirtualizacja i wyzwania związane z ruchem wschód-zachód
Po 2010 roku, aby poprawić wykorzystanie zasobów obliczeniowych i pamięci masowej, centra danych zaczęły wdrażać technologię wirtualizacji, a w sieci pojawiła się duża liczba maszyn wirtualnych. Technologia wirtualna przekształca serwer w wiele serwerów logicznych, z których każda może działać niezależnie, ma własny system operacyjny, aplikację, niezależny adres MAC i adres IP oraz łączy się z jednostką zewnętrzną za pośrednictwem przełącznika wirtualnego (vSwitch) wewnątrz serwera.
Wirtualizacja wiąże się z dodatkowym wymogiem: migracją maszyn wirtualnych w czasie rzeczywistym, czyli możliwością przenoszenia systemu maszyn wirtualnych z jednego serwera fizycznego na inny, przy jednoczesnym zachowaniu normalnego działania usług na tych serwerach. Proces ten jest niezależny od użytkowników końcowych, a administratorzy mogą elastycznie alokować zasoby serwerów lub naprawiać i modernizować serwery fizyczne bez zakłócania normalnego użytkowania przez użytkowników.
Aby zagwarantować, że usługa nie zostanie przerwana podczas migracji, wymagane jest nie tylko zachowanie niezmienionego adresu IP maszyny wirtualnej, ale także zachowanie stanu działania maszyny wirtualnej (takiego jak stan sesji TCP) podczas migracji. W związku z tym dynamiczna migracja maszyny wirtualnej może zostać przeprowadzona tylko w tej samej domenie warstwy 2, ale nie poprzez migrację domeny warstwy 2. Stwarza to potrzebę większych domen L2 od warstwy dostępu do warstwy rdzenia.
Punktem podziału między warstwami L2 i L3 w tradycyjnej architekturze sieci dużej warstwy 2 jest przełącznik rdzeniowy, a centrum danych poniżej przełącznika rdzeniowego jest kompletną domeną rozgłoszeniową, czyli siecią L2. W ten sposób można zrealizować dowolność wdrażania urządzeń i migracji lokalizacji, bez konieczności modyfikowania konfiguracji IP i bramy. Różne sieci L2 (VLans) są kierowane przez przełączniki rdzeniowe. Jednak przełącznik rdzeniowy w tej architekturze musi utrzymywać ogromną tablicę MAC i ARP, co stawia wysokie wymagania dotyczące wydajności przełącznika rdzeniowego. Ponadto przełącznik dostępowy (TOR) ogranicza również skalę całej sieci. To ostatecznie ogranicza skalę sieci, jej rozbudowę i elastyczność, a problem opóźnień w trzech warstwach harmonogramowania nie może sprostać potrzebom przyszłego biznesu.
Z drugiej strony, ruch wschód-zachód generowany przez technologię wirtualizacji stwarza również wyzwania dla tradycyjnej sieci trójwarstwowej. Ruch w centrach danych można ogólnie podzielić na następujące kategorie:
Ruch północ-południe:Ruch pomiędzy klientami spoza centrum danych a serwerem centrum danych lub ruch z serwera centrum danych do Internetu.
Ruch wschód-zachód:Ruch pomiędzy serwerami w centrum danych, a także ruch pomiędzy różnymi centrami danych, taki jak odzyskiwanie danych po awarii pomiędzy centrami danych, komunikacja pomiędzy chmurami prywatnymi i publicznymi.
Wprowadzenie technologii wirtualizacji sprawia, że wdrażanie aplikacji staje się coraz bardziej rozproszone, a „efektem ubocznym” jest zwiększenie ruchu wschód-zachód.
Tradycyjne architektury trójwarstwowe są zwykle projektowane z myślą o ruchu północ-południe.Choć można go używać w ruchu wschód-zachód, ostatecznie może nie spełniać oczekiwań.
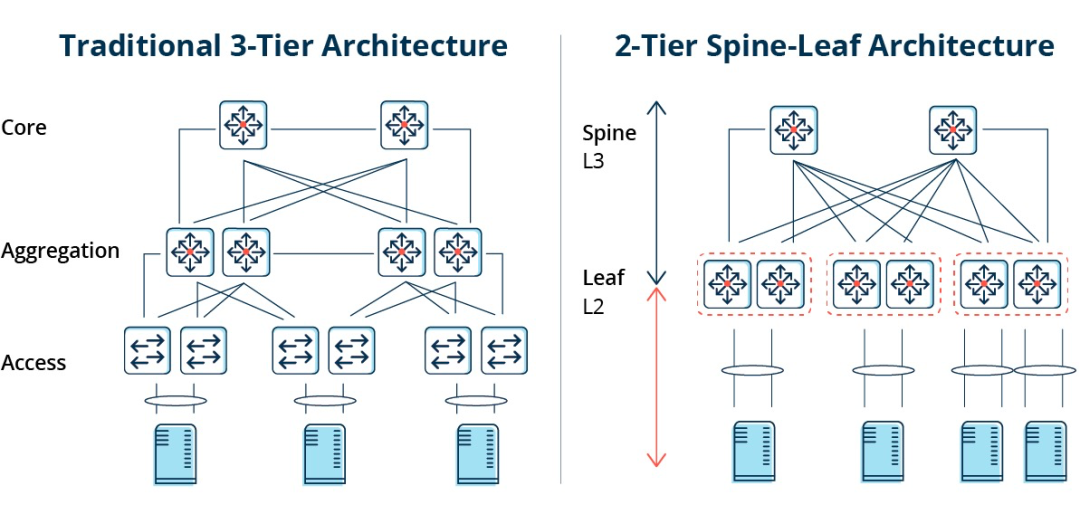
Tradycyjna architektura trójwarstwowa kontra architektura Spine-Leaf
W architekturze trójwarstwowej ruch wschód-zachód musi być przekazywany przez urządzenia w warstwie agregacji i rdzenia. Niepotrzebnie przechodzi przez wiele węzłów. (Serwer -> Dostęp -> Agregacja -> Przełącznik rdzenia -> Agregacja -> Przełącznik dostępu -> Serwer)
W związku z tym, jeśli duża ilość ruchu wschód-zachód jest przesyłana przez tradycyjną trójwarstwową architekturę sieciową, urządzenia podłączone do tego samego portu przełącznika mogą konkurować o przepustowość, co może skutkować dłuższym czasem reakcji uzyskiwanym przez użytkowników końcowych.
Wady tradycyjnej architektury sieci trójwarstwowej
Jak widać, tradycyjna architektura sieci trójwarstwowej ma wiele wad:
Marnowanie przepustowości:Aby zapobiec powstawaniu pętli, protokół STP jest zwykle uruchamiany pomiędzy warstwą agregacji a warstwą dostępu, tak aby tylko jedno łącze uplink przełącznika dostępowego faktycznie przesyłało ruch, a pozostałe łącza uplink będą blokowane, co powoduje marnowanie przepustowości.
Trudności w rozmieszczaniu sieci na dużą skalę:Wraz ze wzrostem skali sieci, centra danych są rozproszone w różnych lokalizacjach geograficznych, maszyny wirtualne muszą być tworzone i migrowane w dowolnym miejscu, a ich atrybuty sieciowe, takie jak adresy IP i bramy, pozostają niezmienione, co wymaga obsługi grubej warstwy 2. W tradycyjnej strukturze nie można przeprowadzić migracji.
Brak ruchu wschód-zachód:Trójwarstwowa architektura sieci jest zaprojektowana głównie dla ruchu północ-południe, choć obsługuje również ruch wschód-zachód, jednak jej wady są oczywiste. Przy dużym ruchu wschód-zachód obciążenie przełączników warstwy agregacji i rdzenia znacznie wzrasta, a rozmiar i wydajność sieci będą ograniczone do warstwy agregacji i rdzenia.
To stawia przedsiębiorstwa przed dylematem kosztów i skalowalności:Obsługa dużych sieci o wysokiej wydajności wymaga dużej liczby urządzeń warstwy konwergencji i rdzenia, co nie tylko generuje wysokie koszty dla przedsiębiorstw, ale także wymaga wcześniejszego zaplanowania sieci już na etapie jej budowy. Mała skala sieci powoduje marnotrawstwo zasobów, a jej dalszy wzrost utrudnia jej rozbudowę.
Architektura sieci Spine-Leaf
Czym jest architektura sieci Spine-Leaf?
W odpowiedzi na powyższe problemy,pojawił się nowy projekt centrum danych, architektura sieciowa Spine-Leaf, którą nazywamy siecią Leaf Ridge.
Jak sama nazwa wskazuje, architektura ta ma warstwę kręgosłupa i warstwę liści, w tym przełączniki kręgosłupa i przełączniki liści.
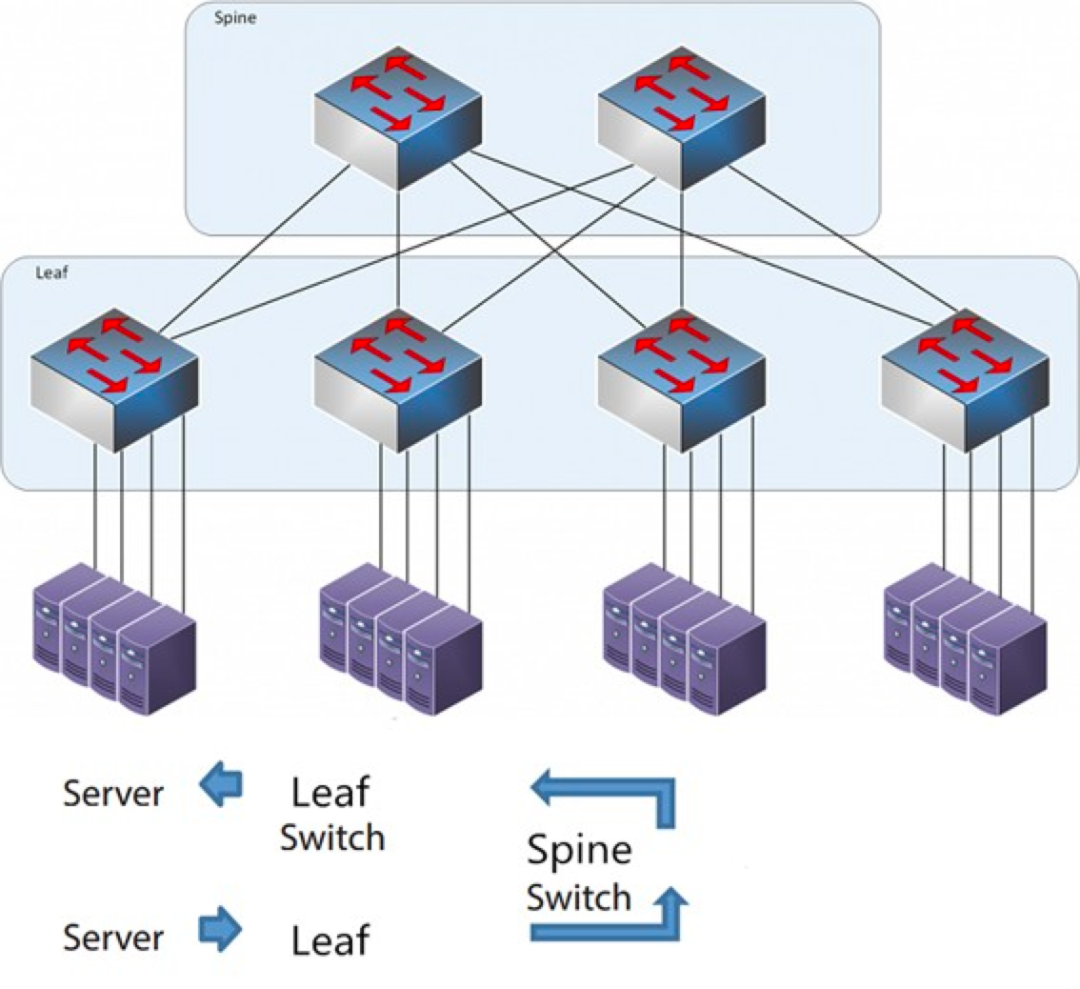
Architektura Spine-Leaf
Każdy przełącznik liściowy jest połączony ze wszystkimi przełącznikami grzbietowymi, które nie są bezpośrednio połączone ze sobą, tworząc topologię pełnej siatki.
W architekturze spine-and-leaf połączenie między serwerami przechodzi przez taką samą liczbę urządzeń (serwer -> leaf -> przełącznik spine -> przełącznik leaf -> serwer), co zapewnia przewidywalne opóźnienie. Ponieważ pakiet musi przejść tylko przez jeden spine i drugi leaf, aby dotrzeć do celu.
Jak działa Spine-Leaf?
Przełącznik Leaf: Jest odpowiednikiem przełącznika dostępowego w tradycyjnej architekturze trójwarstwowej i łączy się bezpośrednio z serwerem fizycznym jako TOR (Top Of Rack). Różnica w stosunku do przełącznika dostępowego polega na tym, że punkt demarkacyjny sieci L2/L3 znajduje się teraz na przełączniku Leaf. Przełącznik Leaf znajduje się nad siecią trójwarstwową, a przełącznik Leaf poniżej niezależnej domeny rozgłoszeniowej L2, co rozwiązuje problem BUM w dużej sieci dwuwarstwowej. Aby dwa serwery Leaf mogły się komunikować, muszą użyć routingu L3 i przekazać go przez przełącznik Spine.
Przełącznik Spine: Odpowiednik przełącznika rdzeniowego. Protokół ECMP (Equal Cost Multi Path) służy do dynamicznego wyboru wielu ścieżek między przełącznikami Spine i Leaf. Różnica polega na tym, że przełącznik Spine zapewnia teraz po prostu odporną sieć routingu L3 dla przełącznika Leaf, dzięki czemu ruch północ-południe w centrum danych może być kierowany z przełącznika Spine, a nie bezpośrednio. Ruch północ-południe może być kierowany z przełącznika brzegowego równolegle do przełącznika Leaf do routera WAN.
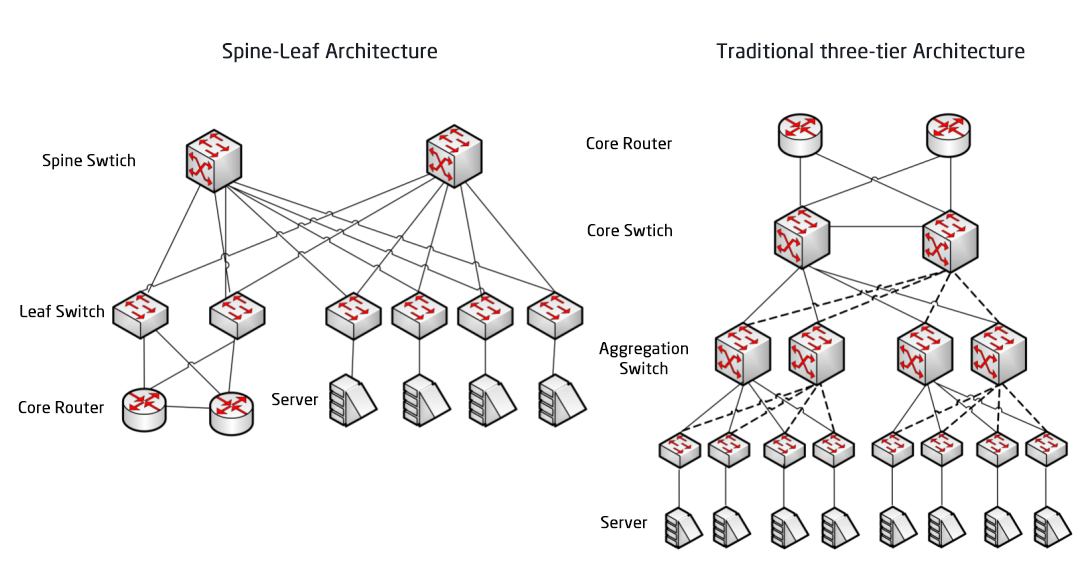
Porównanie architektury sieci Spine/Leaf z tradycyjną architekturą sieci trójwarstwowej
Zalety kolcolistu
Płaski:Płaska konstrukcja skraca ścieżkę komunikacji między serwerami, co skutkuje mniejszymi opóźnieniami, a to może znacząco poprawić wydajność aplikacji i usług.
Dobra skalowalność:Gdy przepustowość jest niewystarczająca, zwiększenie liczby przełączników grzbietowych może zwiększyć przepustowość w poziomie. Wraz ze wzrostem liczby serwerów, jeśli gęstość portów jest niewystarczająca, możemy dodać przełączniki liściowe.
Redukcja kosztów: Ruch w kierunku północnym i południowym, wychodzący z węzłów liściowych lub wychodzący z węzłów grzbietowych. Przepływ wschód-zachód, rozłożony na wielu ścieżkach. W ten sposób sieć grzbietów liściowych może korzystać z przełączników o stałej konfiguracji bez konieczności stosowania drogich przełączników modułowych, co pozwala obniżyć koszty.
Niskie opóźnienia i unikanie przeciążeń:Przepływy danych w sieci Leaf Ridge mają taką samą liczbę przeskoków w sieci, niezależnie od źródła i celu, a dowolne dwa serwery są osiągalne w trzech przeskokach na linii Leaf->Spine->Leaf. To tworzy bardziej bezpośrednią ścieżkę ruchu, co poprawia wydajność i redukuje wąskie gardła.
Wysoki poziom bezpieczeństwa i dostępności:Protokół STP jest używany w tradycyjnej trójwarstwowej architekturze sieciowej. W przypadku awarii urządzenia następuje jego ponowna konwergencja, co wpływa na wydajność sieci, a nawet ją uniemożliwia. W architekturze Leaf-Ride, w przypadku awarii urządzenia, ponowna konwergencja nie jest konieczna, a ruch nadal odbywa się innymi, standardowymi ścieżkami. Łączność sieciowa nie jest zakłócana, a przepustowość jest ograniczona tylko o jedną ścieżkę, co ma niewielki wpływ na wydajność.
Równoważenie obciążenia za pomocą protokołu ECMP doskonale sprawdza się w środowiskach, w których wykorzystywane są scentralizowane platformy zarządzania siecią, takie jak SDN. SDN pozwala uprościć konfigurację, zarządzanie i przekierowywanie ruchu w przypadku blokady lub awarii łącza, dzięki czemu inteligentna topologia pełnej siatki równoważenia obciążenia jest stosunkowo prosta w konfiguracji i zarządzaniu.
Architektura Spine-Leaf ma jednak pewne ograniczenia:
Jedną z wad jest to, że liczba przełączników zwiększa rozmiar sieci. Centrum danych w architekturze sieciowej Leaf Ridge wymaga zwiększenia liczby przełączników i sprzętu sieciowego proporcjonalnie do liczby klientów. Wraz ze wzrostem liczby hostów, do połączenia z przełącznikiem Ridge potrzebna jest duża liczba przełączników Leaf Ridge.
Bezpośrednie połączenie przełączników grzbietowych i liniowych wymaga dopasowania, a ogólnie rzecz biorąc, rozsądny stosunek szerokości pasma między przełącznikami grzbietowymi i liniowymi nie może przekraczać 3:1.
Na przykład, na przełączniku typu leaf znajduje się 48 klientów o przepustowości 10 Gb/s i łącznej przepustowości portów 480 Gb/s. Jeśli cztery porty uplink 40 Gb/s każdego przełącznika typu leaf zostaną podłączone do przełącznika grzbietowego 40 Gb/s, przepustowość uplinku wyniesie 160 Gb/s. Stosunek ten wynosi 480:160, czyli 3:1. Przepustowość uplinków w centrach danych wynosi zazwyczaj 40 Gb/s lub 100 Gb/s i można ją z czasem migrować z punktu początkowego 40 Gb/s (Nx 40 Gb/s) do 100 Gb/s (Nx 100 Gb/s). Należy pamiętać, że przepustowość uplinku powinna zawsze być szybsza niż przepustowość downlinku, aby nie blokować łącza portów.
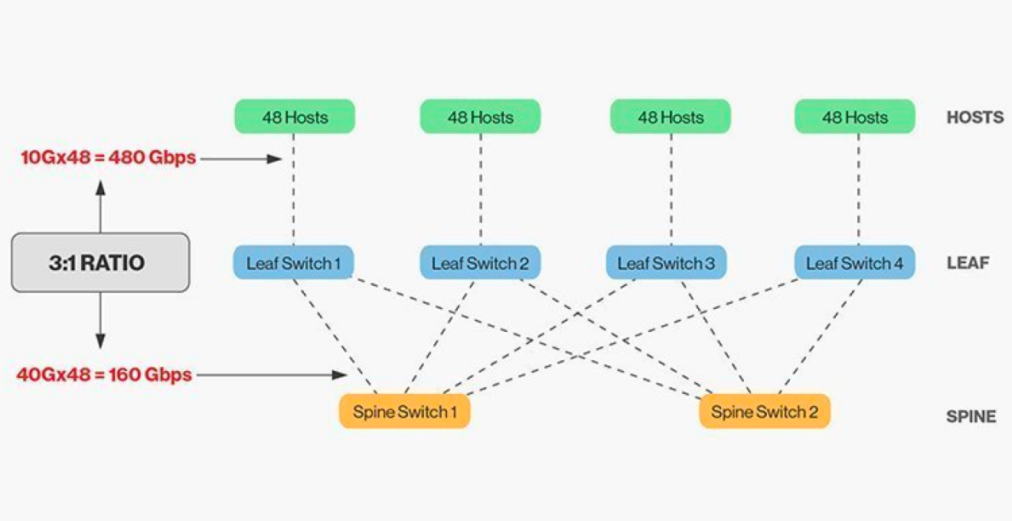
Sieci Spine-Leaf mają również jasno określone wymagania dotyczące okablowania. Ponieważ każdy węzeł typu „liść” musi być podłączony do każdego przełącznika typu „spine”, konieczne jest ułożenie większej liczby kabli miedzianych lub światłowodowych. Odległość między węzłami zwiększa koszty. W zależności od odległości między połączonymi przełącznikami, liczba zaawansowanych modułów optycznych wymaganych przez architekturę Spine-Leaf jest dziesiątki razy większa niż w przypadku tradycyjnej architektury trójwarstwowej, co zwiększa całkowity koszt wdrożenia. Doprowadziło to jednak do rozwoju rynku modułów optycznych, zwłaszcza szybkich modułów optycznych, takich jak 100G i 400G.
Czas publikacji: 26-01-2026



