W dobie szybkich sieci i infrastruktury chmurowej, wydajne monitorowanie ruchu sieciowego w czasie rzeczywistym stało się podstawą niezawodnego działania IT. Wraz ze skalowaniem sieci do obsługi łączy o przepustowości ponad 10 Gb/s, aplikacji konteneryzowanych i architektur rozproszonych, tradycyjne metody monitorowania ruchu – takie jak przechwytywanie pełnych pakietów – nie są już możliwe ze względu na wysokie obciążenie zasobów. W tym miejscu pojawia się sFlow (sampled Flow): lekki, znormalizowany protokół telemetrii sieciowej, zaprojektowany w celu zapewnienia kompleksowej widoczności ruchu sieciowego bez obciążania urządzeń sieciowych. W tym wpisie na blogu odpowiemy na najważniejsze pytania dotyczące sFlow, od jego podstawowej definicji po praktyczne zastosowanie w brokerach pakietów sieciowych (NPB).
1. Czym jest sFlow?
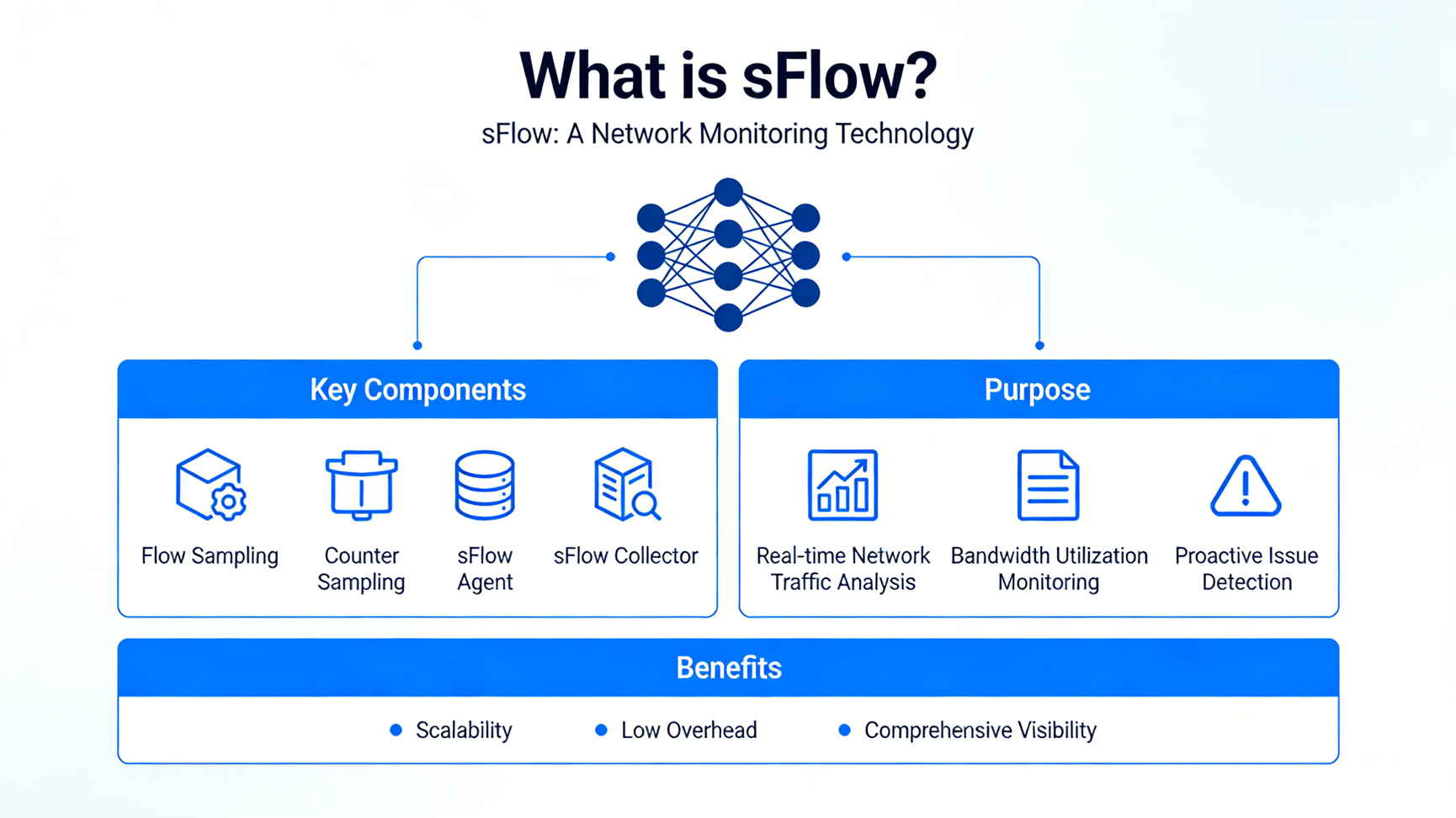
sFlow to otwarty, standardowy w branży protokół monitorowania ruchu sieciowego opracowany przez Inmon Corporation, zdefiniowany w dokumencie RFC 3176. Wbrew temu, co sugeruje nazwa, sFlow nie posiada wbudowanej logiki „śledzenia przepływu” – jest to technologia telemetryczna oparta na próbkowaniu, która gromadzi i eksportuje statystyki ruchu sieciowego do centralnego kolektora w celu analizy. W przeciwieństwie do protokołów stanowych, takich jak NetFlow, sFlow nie przechowuje rekordów przepływu na urządzeniach sieciowych; zamiast tego przechwytuje niewielkie, reprezentatywne próbki ruchu i liczników urządzeń, a następnie niezwłocznie przekazuje te dane do kolektora w celu przetworzenia.
W swojej istocie sFlow został zaprojektowany z myślą o skalowalności i niskim zużyciu zasobów. Jest on wbudowany w urządzenia sieciowe (przełączniki, routery, zapory sieciowe) jako agent sFlow, umożliwiając monitorowanie w czasie rzeczywistym łączy o dużej przepustowości (do 10 Gb/s i większej) bez obniżania wydajności urządzeń ani przepustowości sieci. Standaryzacja zapewnia kompatybilność z rozwiązaniami różnych dostawców, co czyni go uniwersalnym wyborem dla heterogenicznych środowisk sieciowych.
2. Jak działa sFlow?
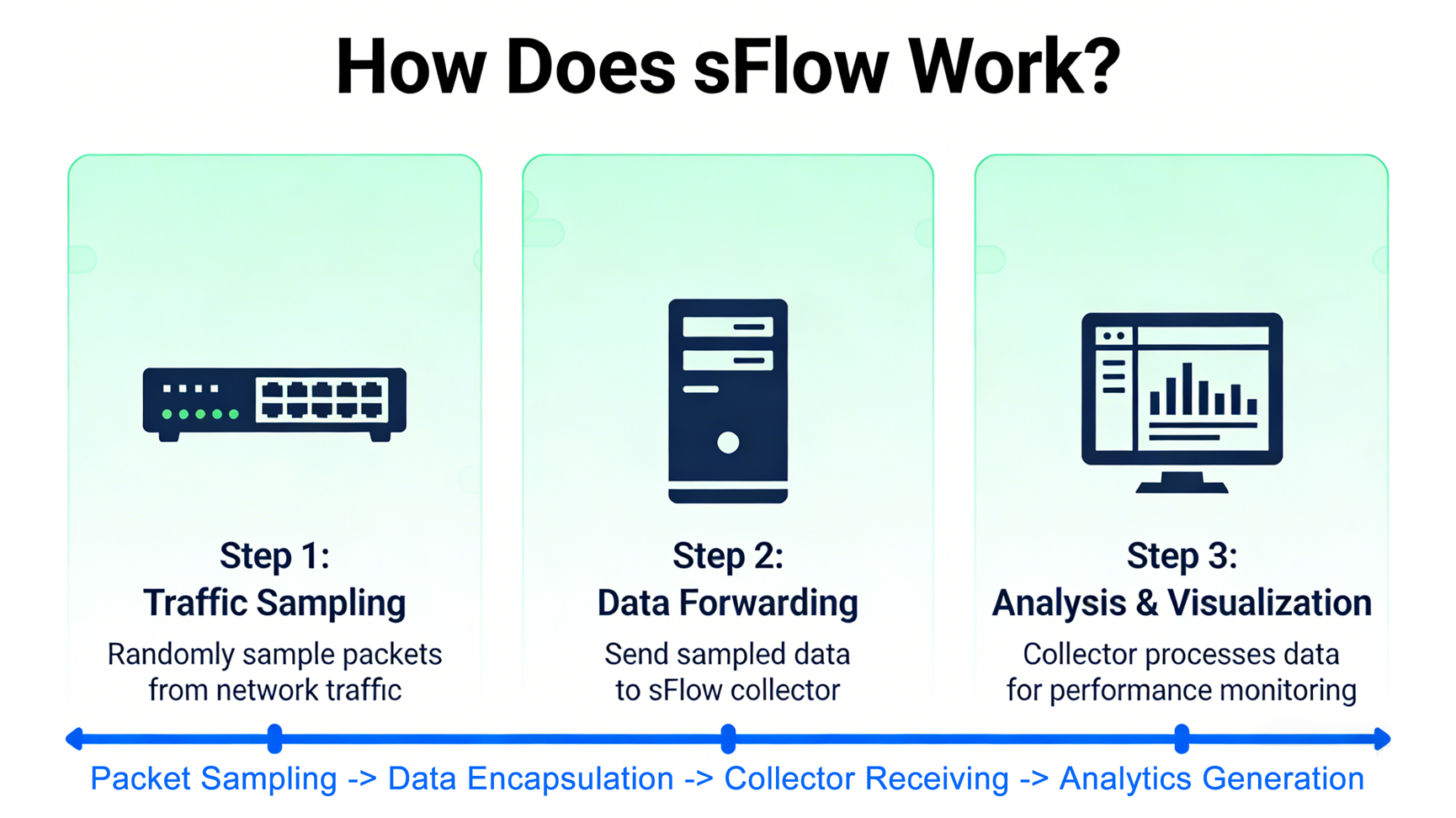
sFlow działa w oparciu o prostą, dwukomponentową architekturę: sFlow Agent (wbudowany w urządzenia sieciowe) i sFlow Collector (scentralizowany serwer do agregacji i analizy danych). Przepływ pracy opiera się na dwóch kluczowych mechanizmach próbkowania – próbkowaniu pakietów i próbkowaniu licznikowym – oraz eksporcie danych, jak opisano poniżej:
2.1 Podstawowe komponenty
- Agent sFlow: Lekki moduł programowy wbudowany w urządzenia sieciowe (np. przełączniki Cisco, routery Huawei). Odpowiada za zbieranie próbek ruchu i danych licznikowych, enkapsulację tych danych w datagramy sFlow i wysyłanie ich do kolektora za pośrednictwem protokołu UDP (domyślny port 6343).
- Kolektor sFlow: scentralizowany system (fizyczny lub wirtualny), który odbiera, analizuje, przechowuje i analizuje datagramy sFlow. W przeciwieństwie do kolektorów NetFlow, kolektory sFlow muszą obsługiwać surowe nagłówki pakietów (zwykle 60–140 bajtów na próbkę) i analizować je, aby uzyskać wartościowe informacje – ta elastyczność umożliwia obsługę niestandardowych pakietów, takich jak MPLS, VXLAN i GRE.
2.2 Kluczowe mechanizmy pobierania próbek
sFlow wykorzystuje dwie uzupełniające się metody próbkowania, aby zrównoważyć widoczność i efektywność wykorzystania zasobów:
1. Próbkowanie pakietów: Agent losowo próbkuje pakiety przychodzące/wychodzące na monitorowanych interfejsach. Na przykład częstotliwość próbkowania 1:2048 oznacza, że Agent przechwytuje 1 na 2048 pakietów (domyślna częstotliwość próbkowania dla większości urządzeń). Zamiast przechwytywać całe pakiety, zbiera tylko kilka pierwszych bajtów nagłówka pakietu (zwykle 60–140 bajtów), które zawierają krytyczne informacje (adres IP źródłowy/docelowy, port, protokół), minimalizując jednocześnie obciążenie. Częstotliwość próbkowania jest konfigurowalna i powinna być dostosowywana do natężenia ruchu sieciowego – wyższe częstotliwości (więcej próbek) poprawiają dokładność, ale zwiększają wykorzystanie zasobów, podczas gdy niższe częstotliwości zmniejszają obciążenie, ale mogą pomijać rzadkie wzorce ruchu.
2. Próbkowanie liczników: Oprócz próbek pakietów, Agent okresowo zbiera dane liczników z interfejsów sieciowych (np. liczbę wysłanych/odebranych bajtów, liczbę utraconych pakietów, wskaźniki błędów) w stałych odstępach czasu (domyślnie: 10 sekund). Dane te dostarczają kontekstu dotyczącego stanu urządzenia i łącza, uzupełniając próbki pakietów i dając pełny obraz wydajności sieci.
2.3 Eksport i analiza danych
Po zebraniu, agent hermetyzuje próbki pakietów i dane licznikowe w datagramy sFlow (pakiety UDP) i wysyła je do kolektora. Kolektor analizuje te datagramy, agreguje dane i generuje wizualizacje, raporty lub alerty. Na przykład, może identyfikować najaktywniejszych rozmówców, wykrywać nietypowe wzorce ruchu (np. ataki DDoS) lub śledzić wykorzystanie przepustowości w czasie. Częstotliwość próbkowania jest uwzględniana w każdym datagramie, co pozwala kolektorowi ekstrapolować dane w celu oszacowania całkowitego wolumenu ruchu (np. 1 próbka na 2048 oznacza ~2048-krotność obserwowanego ruchu).
3. Jaka jest podstawowa wartość sFlow?
Wartość sFlow wynika z unikalnego połączenia skalowalności, niskich kosztów ogólnych i standaryzacji, co pozwala sprostać kluczowym problemom nowoczesnego monitorowania sieci. Jego podstawowe wartości to:
3.1 Niskie obciążenie zasobów
W przeciwieństwie do pełnego przechwytywania pakietów (które wymaga przechowywania i przetwarzania każdego pakietu) lub protokołów stanowych, takich jak NetFlow (które przechowują tabele przepływu na urządzeniach), sFlow wykorzystuje próbkowanie i unika lokalnego przechowywania danych. Minimalizuje to obciążenie procesora, pamięci i przepustowości w urządzeniach sieciowych, co czyni go idealnym rozwiązaniem dla szybkich łączy i środowisk o ograniczonych zasobach (np. sieci małych i średnich przedsiębiorstw). Nie wymaga on dodatkowego sprzętu ani modernizacji pamięci w większości urządzeń, co obniża koszty wdrożenia.
3.2 Wysoka skalowalność
Rozwiązanie sFlow zostało zaprojektowane z myślą o skalowalności w nowoczesnych sieciach. Pojedynczy kolektor może monitorować dziesiątki tysięcy interfejsów na setkach urządzeń, obsługując łącza o przepustowości do 100 Gb/s i większej. Mechanizm próbkowania zapewnia, że nawet przy wzroście natężenia ruchu, wykorzystanie zasobów agenta pozostaje na rozsądnym poziomie, co ma kluczowe znaczenie dla centrów danych i sieci klasy operatorskiej o dużym obciążeniu ruchem.
3.3 Kompleksowa widoczność sieci
Łącząc próbkowanie pakietów (w celu sprawdzenia zawartości ruchu) i próbkowanie liczników (w celu sprawdzenia stanu urządzenia/łącza), sFlow zapewnia kompleksowy wgląd w ruch sieciowy. Obsługuje ruch od warstwy 2 do warstwy 7, umożliwiając monitorowanie aplikacji (np. web, P2P, DNS), protokołów (np. TCP, UDP, MPLS) oraz zachowań użytkowników. Ta widoczność pomaga zespołom IT wykrywać wąskie gardła, rozwiązywać problemy i proaktywnie optymalizować wydajność sieci.
3.4 Standaryzacja niezależna od dostawcy
Jako otwarty standard (RFC 3176), sFlow jest obsługiwany przez wszystkich głównych dostawców rozwiązań sieciowych (Cisco, Huawei, Juniper, Arista) i integruje się z popularnymi narzędziami do monitorowania (np. PRTG, SolarWinds, sFlow-RT). Eliminuje to uzależnienie od dostawcy i pozwala organizacjom korzystać z sFlow w heterogenicznych środowiskach sieciowych (np. na mieszanych urządzeniach Cisco i Huawei).
4. Typowe scenariusze zastosowań sFlow
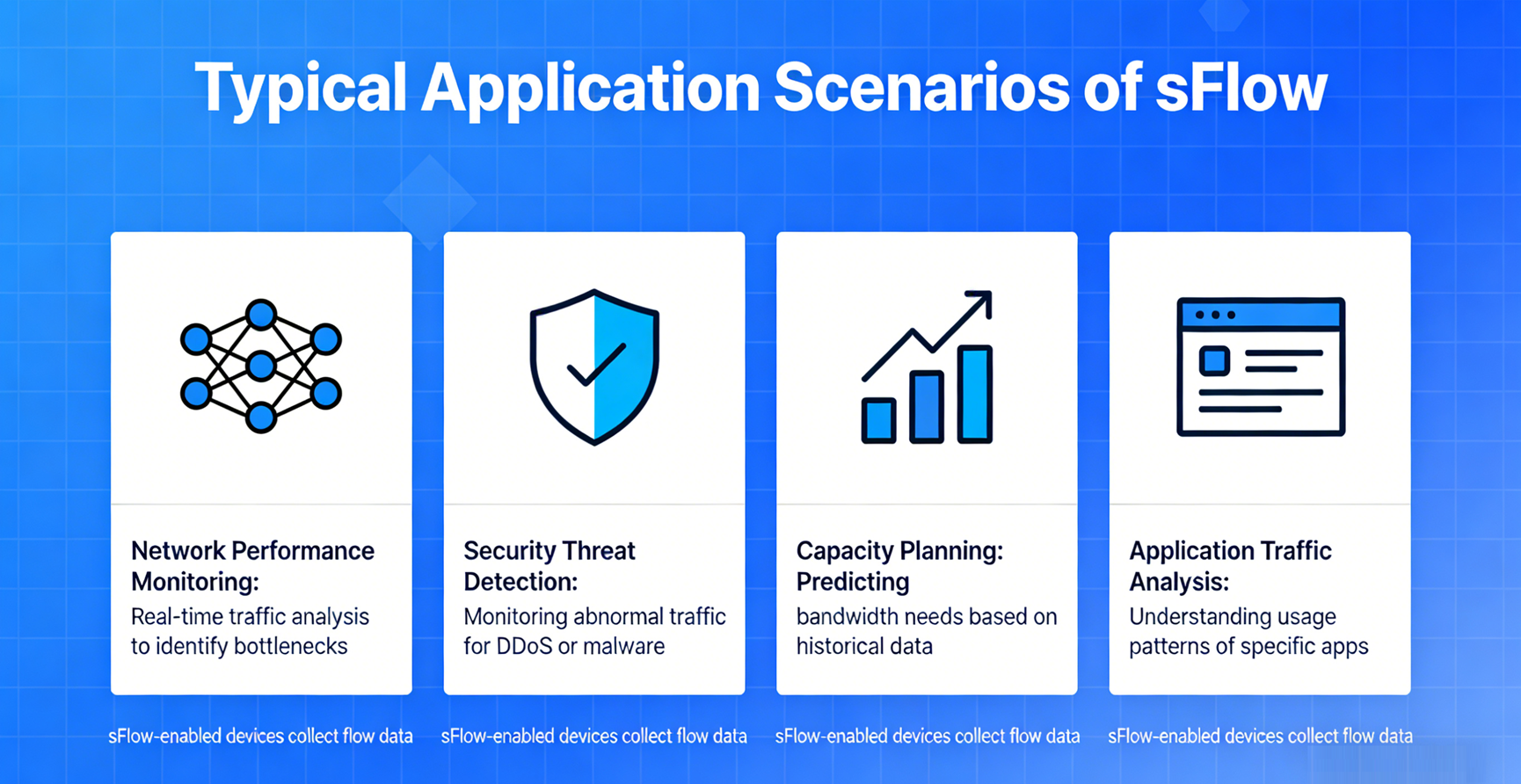
Wszechstronność sFlow sprawia, że nadaje się on do szerokiej gamy środowisk sieciowych, od małych przedsiębiorstw po duże centra danych. Jego najczęstsze scenariusze zastosowań obejmują:
4.1 Monitorowanie sieci centrum danych
Centra danych korzystają z szybkich łączy (ponad 10 Gb/s) i obsługują tysiące maszyn wirtualnych (VM) oraz aplikacji konteneryzowanych. sFlow zapewnia wgląd w czasie rzeczywistym w ruch sieciowy typu „lephant flow”, pomagając zespołom IT wykrywać „słonie” (duże, długotrwałe przepływy powodujące przeciążenia), optymalizować alokację przepustowości i rozwiązywać problemy z komunikacją między maszynami wirtualnymi/kontenerami. Jest często używany w sieciach definiowanych programowo (SDN), aby umożliwić dynamiczną inżynierię ruchu.
4.2 Zarządzanie siecią kampusową przedsiębiorstwa
Przedsiębiorstwa w kampusach potrzebują ekonomicznego, skalowalnego monitoringu, który pozwoli śledzić ruch pracowników, egzekwować zasady dotyczące przepustowości i wykrywać anomalie (np. nieautoryzowane urządzenia, udostępnianie plików P2P). Niskie obciążenie sFlow sprawia, że idealnie nadaje się do przełączników i routerów w kampusach, umożliwiając zespołom IT identyfikację urządzeń zużywających dużą przepustowość, optymalizację wydajności aplikacji (np. Microsoft 365, Zoom) i zapewnienie niezawodnej łączności użytkownikom końcowym.
4.3 Operacje sieciowe klasy operatorskiej
Operatorzy telekomunikacyjni używają sFlow do monitorowania sieci szkieletowych i dostępowych, śledząc natężenie ruchu, opóźnienia i wskaźniki błędów w tysiącach interfejsów. Pomaga operatorom optymalizować relacje peeringowe, wcześnie wykrywać ataki DDoS i rozliczać klientów na podstawie wykorzystania pasma (rozliczanie wykorzystania).
4.4 Monitorowanie bezpieczeństwa sieci
sFlow to cenne narzędzie dla zespołów ds. bezpieczeństwa, ponieważ potrafi wykrywać nietypowe wzorce ruchu związane z atakami DDoS, skanowaniem portów lub złośliwym oprogramowaniem. Analizując próbki pakietów, osoby zbierające dane mogą identyfikować nietypowe pary adresów IP źródło/docelowy, nieoczekiwane użycie protokołów lub nagłe skoki ruchu, co generuje alerty w celu dalszej analizy. Obsługa surowych nagłówków pakietów sprawia, że sFlow jest szczególnie skuteczny w wykrywaniu niestandardowych wektorów ataku (np. szyfrowanego ruchu DDoS).
4.5 Planowanie wydajności i analiza trendów
Gromadząc historyczne dane o ruchu, sFlow umożliwia zespołom IT identyfikację trendów (np. sezonowych skoków przepustowości, rosnącego wykorzystania aplikacji) i proaktywne planowanie modernizacji sieci. Na przykład, jeśli dane sFlow pokazują, że wykorzystanie przepustowości rośnie o 20% rocznie, zespoły mogą zaplanować budżet na dodatkowe łącza lub modernizację urządzeń, zanim wystąpi przeciążenie.
5. Ograniczenia sFlow
Chociaż sFlow to potężne narzędzie monitorujące, ma ono jednak pewne ograniczenia, które organizacje muszą wziąć pod uwagę podczas wdrażania:
5.1 Kompromis w zakresie dokładności próbkowania
Największym ograniczeniem sFlow jest zależność od próbkowania. Niskie częstotliwości próbkowania (np. 1:10 000) mogą pomijać rzadkie, ale krytyczne wzorce ruchu (np. krótkotrwałe przepływy ataków), podczas gdy wysokie częstotliwości próbkowania zwiększają obciążenie zasobów. Ponadto próbkowanie wprowadza wariancję statystyczną – szacunki całkowitego wolumenu ruchu mogą nie być w 100% dokładne, co może być problematyczne w przypadkach użycia wymagających precyzyjnego zliczania ruchu (np. rozliczanie usług o znaczeniu krytycznym).
5.2 Brak pełnego kontekstu przepływu
W przeciwieństwie do NetFlow (który rejestruje kompletne rekordy przepływów, w tym czas rozpoczęcia/zakończenia oraz całkowitą liczbę bajtów/pakietów na przepływ), sFlow rejestruje tylko pojedyncze próbki pakietów. Utrudnia to śledzenie pełnego cyklu życia przepływu (np. identyfikację momentu rozpoczęcia przepływu, jego czasu trwania lub całkowitego zużycia przepustowości).
5.3 Ograniczone wsparcie dla niektórych interfejsów/trybów
Wiele urządzeń sieciowych obsługuje sFlow tylko na interfejsach fizycznych – interfejsy wirtualne (np. podinterfejsy VLAN, kanały portów) lub tryby stosu mogą nie być obsługiwane. Na przykład przełączniki Cisco nie obsługują sFlow po uruchomieniu w trybie stosu, co ogranicza jego zastosowanie we wdrożeniach przełączników w stosie.
5.4 Zależność od implementacji agenta
Skuteczność sFlow zależy od jakości implementacji agenta na urządzeniach sieciowych. Niektóre urządzenia niskiej klasy lub starszy sprzęt mogą mieć słabo zoptymalizowane agenty, które albo zużywają zbyt dużo zasobów, albo dostarczają niedokładne próbki. Na przykład niektóre routery mają wolne procesory płaszczyzny sterowania, które uniemożliwiają ustawienie optymalnych częstotliwości próbkowania, zmniejszając dokładność wykrywania ataków takich jak DDoS.
5.5 Ograniczony wgląd w zaszyfrowany ruch
sFlow przechwytuje tylko nagłówki pakietów – zaszyfrowany ruch (np. TLS 1.3) ukrywa dane ładunku, uniemożliwiając identyfikację faktycznej aplikacji lub zawartości przepływu. Chociaż sFlow nadal może śledzić podstawowe metryki (np. źródło/miejsce docelowe, rozmiar pakietu), nie zapewnia dogłębnego wglądu w zachowanie szyfrowanego ruchu (np. złośliwe ładunki ukryte w ruchu HTTPS).
5.6 Złożoność kolektora
W przeciwieństwie do NetFlow (który zapewnia wstępnie przeanalizowane rekordy przepływu), sFlow wymaga od kolektorów analizy surowych nagłówków pakietów. Zwiększa to złożoność wdrażania i zarządzania kolektorami, ponieważ zespoły muszą upewnić się, że kolektor obsługuje różne typy pakietów i protokoły (np. MPLS, VXLAN).
6. Jak działa sFlow wBroker pakietów sieciowych (NPB)?
Broker pakietów sieciowych (NPB) to specjalistyczne urządzenie, które agreguje, filtruje i dystrybuuje ruch sieciowy do narzędzi monitorujących (np. kolektorów sFlow, systemów IDS/IPS, systemów przechwytywania pełnego pakietu). NPB działają jak „centra ruchu”, zapewniając, że narzędzia monitorujące otrzymują tylko niezbędny ruch, co poprawia wydajność i zmniejsza przeciążenie narzędzi. Po zintegrowaniu z sFlow, NPB zwiększają możliwości sFlow, usuwając jego ograniczenia i zwiększając jego widoczność.
6.1 Rola NPB we wdrożeniach sFlow
W tradycyjnych wdrożeniach sFlow każde urządzenie sieciowe (przełącznik, router) uruchamia agenta sFlow, który wysyła próbki bezpośrednio do kolektora. Może to prowadzić do przeciążenia kolektora w dużych sieciach (np. tysiącach urządzeń wysyłających datagramy UDP jednocześnie) i utrudnia filtrowanie nieistotnego ruchu. NPB rozwiązują ten problem, działając jako scentralizowany agent sFlow lub agregator ruchu w następujący sposób:
6.2 Kluczowe tryby integracji
1. Scentralizowane próbkowanie sFlow: NPB agreguje ruch z wielu urządzeń sieciowych (za pośrednictwem portów SPAN/RSPAN lub TAP), a następnie uruchamia agenta sFlow w celu próbkowania tego zagregowanego ruchu. Zamiast wysyłania próbek do kolektora przez każde urządzenie, NPB wysyła pojedynczy strumień próbek, co zmniejsza obciążenie kolektora i upraszcza zarządzanie. Ten tryb jest idealny dla dużych sieci, ponieważ centralizuje próbkowanie i zapewnia spójną częstotliwość próbkowania w całej sieci.
2. Filtrowanie i optymalizacja ruchu: NPB mogą filtrować ruch przed próbkowaniem, zapewniając, że tylko istotny ruch (np. ruch z krytycznych podsieci, określonych aplikacji) jest próbkowany przez agenta sFlow. Zmniejsza to liczbę próbek wysyłanych do kolektora, poprawiając wydajność i redukując zapotrzebowanie na pamięć masową. Na przykład NPB może filtrować wewnętrzny ruch administracyjny (np. SSH, SNMP), który nie wymaga monitorowania, koncentrując sFlow na ruchu użytkowników i aplikacji.
3. Agregacja i korelacja próbek: NPB mogą agregować próbki sFlow z wielu urządzeń, a następnie korelować te dane (np. łącząc ruch z jednego źródłowego adresu IP z wieloma miejscami docelowymi) przed wysłaniem ich do kolektora. Zapewnia to kolektorowi pełniejszy obraz przepływów sieciowych, rozwiązując ograniczenie sFlow polegające na braku śledzenia pełnych kontekstów przepływów. Niektóre zaawansowane NPB obsługują również dynamiczną regulację częstotliwości próbkowania w zależności od natężenia ruchu (np. zwiększając częstotliwość próbkowania podczas szczytów ruchu w celu poprawy dokładności).
4. Nadmiarowość i wysoka dostępność: NPB mogą zapewnić redundantne ścieżki dla próbek sFlow, gwarantując brak utraty danych w przypadku awarii kolektora. Mogą również równoważyć obciążenie próbek na wiele kolektorów, zapobiegając sytuacji, w której pojedynczy kolektor stanie się wąskim gardłem.
6.3 Praktyczne korzyści z integracji NPB + sFlow
Integracja sFlow z NPB zapewnia szereg kluczowych korzyści:
- Skalowalność: NPB zajmują się agregacją i próbkowaniem ruchu, co pozwala kolektorowi sFlow na skalowanie w celu obsługi tysięcy urządzeń bez przeciążenia.
- Dokładność: Dynamiczna regulacja częstotliwości próbkowania i filtrowanie ruchu poprawiają dokładność danych sFlow, redukując ryzyko pominięcia krytycznych wzorców ruchu.
- Wydajność: Centralne pobieranie próbek i filtrowanie zmniejsza liczbę próbek wysyłanych do kolektora, co obniża zużycie przepustowości i pamięci masowej.
- Uproszczone zarządzanie: NPB centralizują konfigurację i monitorowanie sFlow, eliminując potrzebę konfigurowania agentów na każdym urządzeniu sieciowym.
Wniosek
sFlow to lekki, skalowalny i znormalizowany protokół monitorowania sieci, który odpowiada na specyficzne wyzwania nowoczesnych sieci o dużej przepustowości. Wykorzystując próbkowanie do zbierania danych o ruchu i danych licznikowych, zapewnia kompleksową widoczność bez obniżania wydajności urządzenia, co czyni go idealnym rozwiązaniem dla centrów danych, przedsiębiorstw i operatorów. Chociaż ma on ograniczenia (np. dokładność próbkowania, ograniczony kontekst przepływu), można je złagodzić, integrując sFlow z brokerem pakietów sieciowych (Network Packet Broker), który centralizuje próbkowanie, filtruje ruch i zwiększa skalowalność.
Niezależnie od tego, czy monitorujesz małą sieć kampusową, czy dużą sieć szkieletową operatora, sFlow oferuje ekonomiczne, niezależne od dostawcy rozwiązanie, które pozwala uzyskać praktyczne informacje o wydajności sieci. W połączeniu z NPB staje się jeszcze bardziej wydajne – umożliwiając organizacjom skalowanie infrastruktury monitorowania i zachowanie widoczności w miarę rozwoju sieci.
Czas publikacji: 05-02-2026



